2019/07/20追記
この記事を書いてから随分と経過しました。完全に情報が古くなっています。外部のサイトですが必要な場合は以下等を参照して下さい。
PythonとTesseract OCRで文字認識
OpenCVのOCR(tesseract-ocr)をWindows(64bit)、C++で使う
vcpkgとCMakeで簡単にtesseract-ocr
2019/07/20追記ここまで
Tesseract-OCRの導入の3回目です。前回はvc++のコンソールアプリからAPIを使ってみました。今回も同じような使い方ですが、OpenCVでの領域の認識結果をTesseract-OCRのAPIで文字を認識するという流れです。(※OpenCV 3.0系からは文字認識が組み込まれるようです。今回のTesseract-OCRもOpenCVに組み込まれるようです。詳細はページ最後の関連サイト等を参照して下さい。)
今回の処理の流れです。以下のような何となくそれらしい入力用紙をイメージした画像を作成しました。作成したのはExcelでそのスクリーンショットを切り取って保存しました。

まずここからOpenCVで入力領域を切り出します。


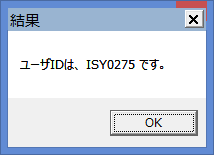
これらをそれぞれTesseract-OCRの入力ファイルとして認識します。以下のように結果が表示されました。

ここからプログラムの説明です。ペースになっているプログラムは以下で作成したプログラムです。
OpenCVで輪郭抽出から隣接領域の切り出し(その1)輪郭抽出まで
このプログラムのプロジェクトに前回までに書いた環境でTesseract-OCRのAPIを使います。前回書いたライブラリのインクルードディレクトリやライブラリファイルの設定も今回のプロジェクトに追加します。
ここまでをベースにして以下のようなプログラムを作成しました。
※ソース全体は以下からダウンロード出来ます。Tesseractのインストール、ライブラリの設定が必要です。必要な場合は前回までを参照して下さい。
プロジェクト一式
(※必要な場合は用途に限らずご利用頂いて問題ありませんが、一切無保証です。弊社は一切の責任を負いません。)
/*------------------------------------------------
処理1
-------------------------------------------------*/
void func1(HWND hWnd)
{
////MessageBox(hWnd, "func1", "debug", MB_OK);
if (imgMatRead.rows == 0){
MessageBox(hWnd, "画像ファイルが無効です", "エラー", MB_OK);
return;
}
//入力画像、ここでは毎回ファイルから読み込む
cv::Mat imgIn = cv::imread((const std::string&)szOpenFileName, 1); //3チャンネルカラー画像で読み込む;
//グレースケール
cv::Mat grayImage, binImage;
cv::cvtColor(imgIn, grayImage, CV_BGR2GRAY);
//2値化(※反転で結果が変わる、基本は背景が黒で物体が白)
//ここでは固定のしきい値を使用する
cv::threshold(grayImage, binImage, 220, 255.0, CV_THRESH_BINARY);
//cv::imshow("bin", binImage);
//輪郭の座標リスト
std::vector< std::vector< cv::Point > > contours;
//輪郭取得
cv::findContours(binImage, contours, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_NONE);
//輪郭の数
int roiCnt = 0;
//輪郭のカウント
int i = 0;
for (auto contour = contours.begin(); contour != contours.end(); contour++){
std::vector< cv::Point > approx;
//輪郭を直線近似する
cv::approxPolyDP(cv::Mat(*contour), approx, 0.01 * cv::arcLength(*contour, true), true);
// 近似の面積が一定以上なら取得
double area = cv::contourArea(approx);
if (area > 1000.0){
//輪郭に隣接する矩形の取得
cv::Rect brect = cv::boundingRect(cv::Mat(approx).reshape(2));
roi[roiCnt] = cv::Mat(grayImage, brect);
//表示
cv::imshow("label" + std::to_string(roiCnt+1), roi[roiCnt]);
if (roiCnt == 0){
imgMatWrite = roi[roiCnt];
}
roiCnt++;
//念のため輪郭をカウント
if (roiCnt == 99)
{
break;
}
}
i++;
}
//ここからTesseractの処理
const int charSize = 1024;
char szTmpPath[charSize]; //作業用ディレクトリ
char userid[charSize]; //ユーザID
char name[charSize]; //名前
char msg[charSize]; //メッセージボックス用
//認識対象画像を一時的に保存するディレクトリを取得する
GetTempPath(sizeof(szTmpPath) / sizeof(szTmpPath[0]),szTmpPath);
strcat(szTmpPath, "\\ocrimg.png");
//Tesseract初期化
tesseract::TessBaseAPI tess;
tess.Init("", "eng", tesseract::OEM_DEFAULT);
//対象画像ごとの処理
for (int i = 0; i < roiCnt; i++){
//一時ファイルに保存
imgMatWrite = roi[i];
cv::imwrite(szTmpPath, imgMatWrite);
//認識開始
STRING text;
tess.ProcessPages(szTmpPath, NULL, 0, &text);
//認識結果の取得
const char* result = text.string();
//ユーザIDの場合
if (strncmp(result, "UserID", 6) == 0){
memset(userid, 0x00, 1024);
strncpy(userid, result + 6, strlen(result) - 6 - 2); //2は改行コードの長さ
sprintf(msg, "ユーザIDは、%s です。", userid);
MessageBox(hWnd, msg, "結果", MB_OK);
}
//名前の場合
if (strncmp(result, "Name", 4) == 0){
memset(name, 0x00, 1024);
strncpy(name, result + 4, strlen(result) - 4 - 2); //2は改行コードの長さ
sprintf(msg, "名前は、%s です。", name);
MessageBox(hWnd, msg, "結果", MB_OK);
}
}
//念のため
tess.Clear();
tess.End();
}
上記ソースは認識の部分のみです。全体が必要な場合はお手数ですがソース一式をダウンロードして参照して下さい。OpenCVの輪郭の認識のプログラムにTesseract-OCRのAPIでの認識を後付けしたような処理ですが以下のようの流れです。
OpenCVで認識出来た輪郭をグレースケールの画像から輪郭画像の配列に保存
↓
輪郭ごとに一時ファイルに保存
↓
一時ファイルをTesseract-OCRで英数字で認識
↓
あらかじめ決めたユーザIDと名前のキーワードがあればユーザID、名前として認識して表示する
OpenCVからTesseract-OCRへは単純にファイルで渡しています。また文字列操作はC言語の関数で処理しています。
まあこれぐらいなら認識出来ましたが日本語も含めてどこまで認識出来るかということになってくると思います。そういった意味でもいろいろと課題があると思いますがとりあえず今回のシリーズとしてはここまでです。
関連サイト
Advanced API
opencvで文字認識その1 Tesseractラッパ – whoopsidaisies’s diary
関連書籍
(※OpenCV 2 プログラミングブックは私も持っています。)
(※ここからはKindle版で英語ですが最新の情報もあるようです。また価格的にはいいかもしれないです。)